
생활공공기관
도구
- 스마트폰,태블릿 화면크기비교
- 양쪽 윈도우키를 한영한자키로(AutoHotKey)
- 매크로: Robotask Lite
- 파일이름변경: ReNamer Lite
- 파일압축: 반디집
- 공공서식 한글(HWP편집가능, 개인비영리)
- 오피스: 리브레오피스(LibreOffice)
- 텍스트뷰어: 이지뷰어
- PDF: FoxIt리더, ezPDF에디터
- 수학풀이: 울프램 알파 ( WolframAlpha )
- 수치해석: 셈툴, MathFreeOn
- 계산기: Microsoft Mathematics 4.0
- 동영상: 팟플레이어
- 영상음악파일변환: 샤나인코더
- 이미지: 포토웍스
- 이미지: FastStone Photo Resizer
- 화면갈무리: 픽픽
- 이미지 편집: Paint.NET, Krita
- 이미지 뷰어: 꿀뷰
Link
- 국립중앙도서관 소장자료 검색
- KS국가표준인증종합정보센터
- 대한무역투자진흥공사(KOTRA) 해외시장뉴스
- 엔팩스(인터넷팩스발송)
- 구글 드라이브(문서도구)
- MS 원드라이브(SkyDrive)
- 네이버 N드라이브
- Box.com (舊 Box.net)
- Dropbox
- 구글 달력
- 모니터/모바일 픽셀 피치 계산
- Intel CPU, 칩셋 정보
- MS윈도우 기본 단축키
- 램디스크
- 초고해상도 관련
- 게임중독
- 표준시각
- 전기요금표/ 한전 사이버지점
- HWP/한컴오피스 뷰어
- 인터넷 속도측정(한국정보화진흥원)
- IT 용어사전
- 우편번호찾기
- 도로명주소 안내, 변환
- TED 강연(네이버, 한글)
- 플라톤아카데미TV
- 세바시
- 명견만리플러스
- 동아사이언스(과학동아)
- 과학동아 라이브러리
- 사이언스타임즈
- 과학잡지 표지 설명기사
- 칸아카데미
- KOCW (한국 오픈 코스웨어) 공개강의
- 네이버 SW 자료실
- 네이버 SW자료실, 기업용 Free
- 계산기
공공데이터베이스
PC Geek's
PDF OCR: 스캔한 텍스트 이미지 PDF에서 text추출, 그리고 스캔한 이미지를 모아 PDF로 본문
저 두 가지 기능이 관심이 가네요. 저도 아직 써보지는 않았는데, 받아봐야곘습니다.
처음에는 PDF파일에서 txt를 뽑아내는 건줄 알았는데, 읽어보니 책을 스캔한 이미지를 PDF로 만든 파일에서 text를 추출하는 것입니다. 즉 OCR처럼 말이죠. 이런 건 무료인 걸 본 적이 없어서 기록해둡니다. 그리고 부가 기능으로, 스캔한 이미지를 pdf파일로 묶어줍니다. 그리고 편집 기능을 제공합니다.
PDF OCR

GAOTD 1일 무료 다운로드: http://www.giveawayoftheday.com/pdf-ocr-ocr-pdf/
제작사 홈페이지: http://www.pdfocr.net/
참고. 10개 언어 이상을 지원한다.. 고 써놨지만 한글은 안 됩니다.
ps.
설치 과정에 업데이트 인포머를 같이 깔 거냐고 묻습니다. 안 해도 쓰는 데는 상관없는 것 같습니다.
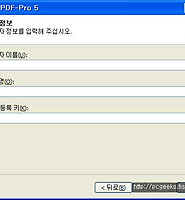
아래는 실행 화면. 설치 종료 후 뜨는 등록 코드를 적어두었다가 실행한 다음 풀다운메뉴 끝에 있는 등록 항목을 클릭해 입력해줍니다. 그리고 재시작하면 됩니다.

처음 실행하면 스캔해 PDF로 묶은 것을 OCR해 텍스트를 뽑아낼 것인지, 아니면 이미지를 PDF로 묶는 작업을 할 것인지 묻습니다.
'소프트웨어와 콘텐츠 > PDF' 카테고리의 다른 글
| PDF-XChange Viewer : 뷰어로는 좋은 프로그램 (0) | 2012.06.22 |
|---|---|
| 폭스잇 리더(foxit reader): PDF 뷰어 (0) | 2012.05.29 |
| ePapyrus PDF-Pro 5 Free: PDF 제작기, 변환기 툴(+가상프린터 드라이버) (3) | 2012.04.26 |
| PDF OCR 4.2: (영문) 스캔한 이미지 파일이나 이미지파일을 묶어 만든 PDF 를 텍스트파일로 변환 (2) | 2012.04.03 |
| Foxonic Professional 4.0: 각종 PDF편집, 변환, 암호화 툴 (~2010.3.16.16시까지) (0) | 2010.03.15 |
| PDF to Word Converter: 이런 종류 중 하나. 무료배포중 (0) | 2010.02.24 |
| Nova PDF 7 light 특징과 메뉴 (0) | 2010.02.04 |
| PDFZilla 1.4일 오후 5시까지무료배포. PDF문서를 다른 포맷으로 변환하는 프로그램 (0) | 2010.01.04 |
Comments


|
Viewed Posts
|
|
Recent Posts
|